11000mAh电池+10000nits高亮屏,“耐用神机”荣耀X80 Pro Max发布
2026-06-22
其中Vi 是第i个模型的大小,C是单个GPU的显存大小。Persia使用贪心算法得到该问题的一个近似解,并依此将不同Embedding均匀分散在不同GPU上,以达到充分利用GPU的目的。当需要精确求解最优的Embedding放置位置时,Persia还可以通过integer optimization给出精确解。
2. 简化小模型多 GPU 分布训练
当模型大小可以放入单个GPU时,Persia也支持切换为目前在图像识别等任务中流行的AllReduce分布训练模式。这样不仅可以使训练算法更加简单,在某些情景下还可以加快训练速度。
使用这种训练模式时,每个GPU都会拥有一个同样的模型,各自获取样本进行梯度计算。在梯度计算后,每个GPU只更新自己显存中的模型。需要注意的是即使模型可以置于一个GPU的显存中,往往Embedding部分也比较大,如果每次更新都同步所有GPU上的模型,会大大拖慢运算速度。因此Persia在AllReduce模式下,每次更新模型后,所有GPU使用AllReduce同步DNN部分,而Embedding部分每隔几个更新才同步一次。这样,即不会损失太多信息,又保持了训练速度。
此外,在TensorFlow上,Persia还支持TensorFlow的"Replicated", "PS", "PS" + "Asynchronous" 模式多卡训练,它们的主要区别如下图:
二、 模型准确度提升
同步更新:由于普遍使用的传统异步 SGD 有梯度的延迟问题,若有n台计算机参与计算,每台计算机的梯度的计算实际上基于n个梯度更新之前的模型。在数学上,对于第t步的模型xt,传统异步SGD的更新为:
xt+1←xt−learning rate×g(xt−τt),
其中g(xt−τt)是训练样本的损失函数在τt 个更新之前的模型上的梯度。而 τt 的大小一般与计算机数量成正比,当计算机数量增多,xt−τt 与 xt 相差就越大,不可避免地导致模型质量的降低。Persia的训练模式在Embedding分片存储时没有这种延迟问题,而在AllReduce模式下也仅在Embedding层有常数量级的延迟,因此模型质量也有所提升。
优化算法:与此同时,Persia还可以使用Adam等momentum optimizer,并为其实现了sparse版本的更新方式,比PyTorch/TensorFlow内置的dense版本更新在广告任务上快3x-5x。这些算法在很多时候可以在同样时间内得到比使用 SGD或Adagrad更好的模型。
三、 训练数据分布式实时处理
快手Persia的高速GPU训练,需要大量数据实时输入到训练机中,由于不同模型对样本的需求不同,对于每个新实验需要的数据格式可能也不同。因此 Persia需要:
· 简单灵活便于修改的数据处理流程,
· 可以轻易并行的程序架构,
· 节约带宽的数据传输方式。
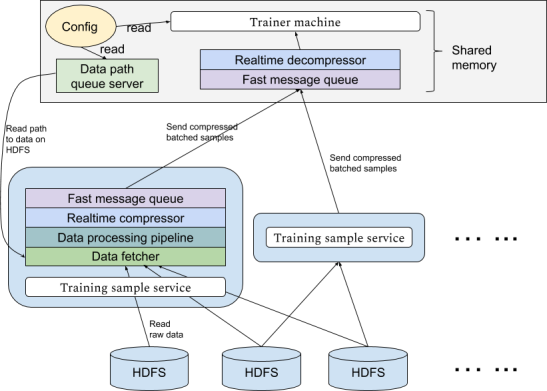
为此,Persia系统实现了基于Hadoop集群的实时数据处理系统,可以应不同实验需求从HDFS中使用任意多计算机分布式读取数据进行多级个性化处理传送到训练机。传输使用高效消息队列,并设置多级缓存。传输过程实时进行压缩以节约带宽资源。
1. 并行数据处理
数据处理pipeline:为了使Persia获取数据的方式更灵活,Persia使用dataflow构建数据处理pipeline。在Persia中可以定义每一步处理,相当于一个函数,输入为上一个处理步骤的输出,输出提供给下一个处理步骤。我们定义这些函数为 {fi}i=1p。在Persia中,这些函数可以单独定义修改。在每个函数的入口和出口,Persia有数据队列缓存,以减少每个函数获取下一个输入的时间。这些函数的运行可以完全并行起来,这也是pipeline的主要目的。以在食堂就餐为例,pipeline的运行就像这样:
数据压缩和传输:全部处理之后,数据处理任务会将数据组成mini-batch并使用zstandard高速压缩每个batch,通过ZeroMQ将压缩数据传输给训练机进行训练。定义batching操作为函数 B,压缩操作为函数C,则每个数据处理任务相当于一个函数C(B(fp(fp−1(⋯f1(raw data from HDFS))))) 。
Queue server:在Hadoop集群中Persia将启动多个数据处理任务,每个数据处理任务之间完全独立。数据处理任务本身并不知道处理哪些数据,而是通过请求训练机得知训练数据的位置。这样的好处是,在Persia中训练机可以应自己需求动态控制使用什么样的训练数据,而数据处理任务相当于一个无状态的服务,即使训练机更换了新的训练任务也不需要重启数据处理任务。具体来说,在Persia中训练机会启动一个queue server进程,该queue server将会应数据处理任务的请求返回下一个需要读取的数据文件。Persia的每个数据处理任务会同时从queue server请求多个文件,并行从HDFS读取这些文件。
整个系统的构造如下图:
2. 实时训练
由于Persia的数据处理任务在获取数据时完全依赖于训练机的指示,Persia支持对刚刚生成的数据进行在线训练的场景,只需要使queue server返回最近生成的数据文件即可。因此,Persia在训练时的数据读取模式上非常灵活,对queue server非常简单的修改即可支持任意数据读取的顺序,甚至可以一边训练一边决定下一步使用什么数据。
3. 更快的数据读取速度:训练机共享内存读取数据
由于训练机要同时接收从不同数据处理任务发送来的大量数据,并进行解压缩和传输给训练进程进行实际训练的操作,接收端必须能够进行并行解压和高速数据传输。为此,Persia使用ZeroMQ device接收多个任务传输而来的压缩数据,并使用多个解压进程读取该device。每个解压进程独立进行解压,并与训练进程共享内存。当结束解压后,解压进程会将可以直接使用的batch样本放入共享内存中,训练任务即可直接使用该batch进行训练,而无需进一步的序列化反序列化操作。
训练效果
Persia系统在单机上目前实现了如下训练效果:
· 数据大小:百T数据。
· 样本数量:25亿训练样本。
· 8卡V100计算机,25Gb带宽:总共1小时训练时间,每秒64万样本。
· 8卡1080Ti计算机,10Gb带宽:总共不到2小时训练时间,每秒40万样本。
· 4卡1080Ti达30万样本/秒,2卡1080Ti达20万样本/秒。
· Persia同样数据上Test AUC高于原ASGD CPU平台。
· Persia支持很大batch size,例如25k。
综上,Persia不仅训练速度上远远超过CPU平台,并且大量节省了计算资源,使得同时尝试多种实验变得非常方便。
展望:分布式多机训练
未来,Persia系统将展开分布式多GPU计算机训练。有别于成熟的计算机视觉等任务,由于在广告任务中模型大小大为增加,传统分布式训练方式面临计算机之间的同步瓶颈会使训练效率大为降低。Persia系统将支持通讯代价更小、系统容灾能力更强的去中心化梯度压缩训练算法。据快手FeDA智能决策实验室负责人刘霁介绍,该算法结合新兴的异步去中心化训练 (Asynchronous decentralized parallel stochastic gradient descent, ICML 2018) 和梯度压缩补偿算法 (Doublesqueeze: parallel stochastic gradient descent with double-pass error-compensated compression, ICML 2019),并有严格理论保证,快手Persia系统在多机情景下预计还将在单机基础上做到数倍到数十倍效率提升。
---------------------------------------------------------
免责声明:
1.本文援引自互联网,旨在传递更多网络信息,仅代表作者本人观点,与本网站无关。
2.本文仅供读者参考,本网站未对该内容进行证实,对其原创性、真实性、完整性、及时性不作任何保证。