

别了,摩尔定律!华为“韬定律”如何改写全球半导体的未来
2026-05-29
2024 年,大模型领域的一个趋势越来越清晰:重视优化,面向应用。
在去年的百模大战中,科技巨头、创业力量你追我赶,将大模型技术卷到了一个新的高度。有了强大的模型之后,更重要的是将这些能力输出到现实中的应用场景,提升用户体验、构建生态。
正因此,大模型厂商们或是开源,或是推出模型 API,都是希望让成果为开发者所用,以此为基础设施构建起繁荣的大模型生态。
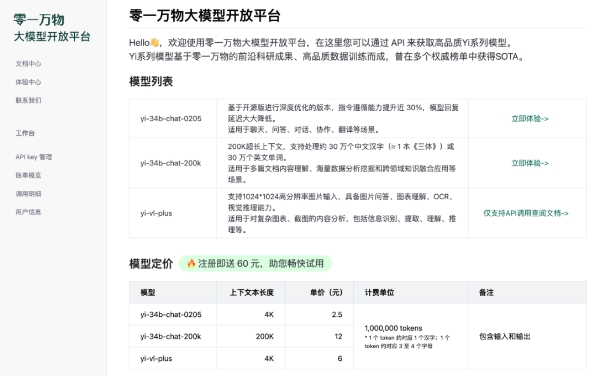
国内的大模型独角兽公司零一万物,也在今天正式发布了 Yi 大模型 API 开放平台。
零一万物 API 开放平台链接:https://platform.lingyiwanwu.com/
此次 API 开放平台提供以下模型:
Yi-34B-Chat-0205:支持通用聊天、问答、对话、写作、翻译等功能。
Yi-34B-Chat-200K:200K 上下文,多文档阅读理解、超长知识库构建小能手。
Yi-VL-Plus: 多模态模型,支持文本、视觉多模态输入,中文图表体验超过 GPT-4V。
实际上,在半个月前,零一万物已经启动了 Yi-34B-Chat-0205 和 Yi-34B-Chat-200K 两个模型的邀测,很多开发者早就上手体验过一波了。
我们围观了一下,发现了几个亮点:
首先,200K 上下文确实强。就拿专业书翻译这件事来说吧,前 HuggingFace 员工、Transformer 核心贡献者 Stas Bekman 写过一本名为《机器学习工程》的电子书。调用 Yi-34B-Chat-200K 之后,知乎知名技术作者「苏洋」一天之内就完成了长达 264 页的书籍翻译工作。
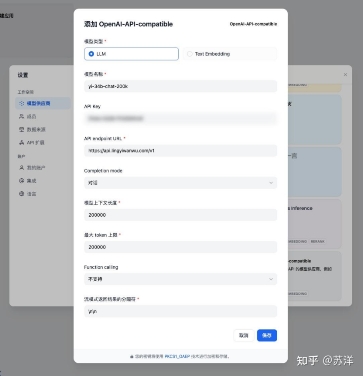
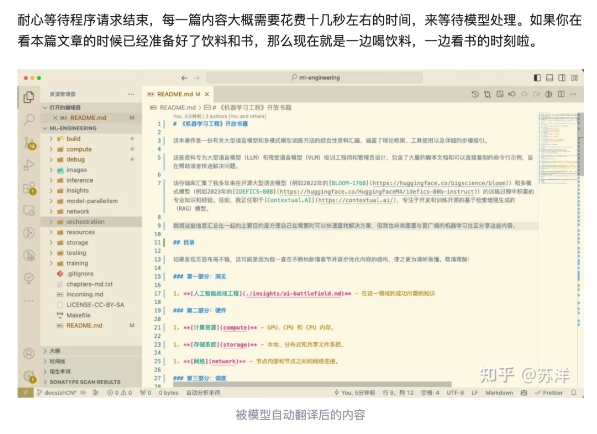
图源:使用零一万物 200K 模型和 Dify 快速搭建模型应用 https://zhuanlan.zhihu.com/p/686774859
其次,在 Yi-34B-Chat-0205、Yi-34B-Chat-200K 之外,零一万物开放平台此次同期上新全新的多模态大模型 Yi-VL-Plus。
Yi-VL-Plus 支持文本、视觉多模态输入,面向实际场景大幅增强。多位用户反馈:「中文体验超过 GPT-4V。」

GPT-4V 连招牌都没看明白。
此外,零一万物 Yi 大模型 API 开放平台和 OpenAI API 是兼容的,迁移方案时的体验应该也非常丝滑。
当然,Yi 大模型 API 到底能不能与 GPT-4 Turbo、Gemini 1.5、Claude 3 这些模型的表现一较高下,还需要更多开发者一起考察。
Yi 大模型 API 名额目前限量开放,零一万物会为新用户免费赠送 60 元,感兴趣的开发者不妨申请体验一下。
200K 上下文的大模型,有多能打?
在此前的内测中,最令人印象深刻的不外乎具有超长上下文窗口的 Yi-34B-Chat-200K。
对于大模型的落地应用,上下文窗口是一项非常关键的因素。过去一年里,各家大模型的上下文窗口都在飞速扩展:OpenAI 把 GPT-4 的 32K 直接提到 GPT-4 Turbo 的 128K。谷歌的 Gemini 1.0 还是 32K,Gemini 1.5 Pro 马上就升级到了 100 万 Token。
前不久,Claude 3 将大模型 API 的上下文长度纪录一下提到了 200K,还宣称有能力开放 100 万 Token 的上下文输入(尽管目前仅限特定客户)。
要完成更复杂的现实任务,模型需要能够处理长篇的上下文。更广阔的上下文窗口能显著提升模型的理解深度,在生成内容或解答问题时实现更高的准确性和相关性。这是因为模型能够「回忆」并参照较长的文本历史,面对长文章、书籍的章节、复杂对话或其他需长期累积上下文的情境时,这种能力格外关键。
Yi-34B-Chat-200K 能够处理大约 30 万个中英文字符。我们可以拿文学类书籍来类比,32K 就像是一篇 2 万字的短篇小说(比如《潜伏》原著),128K 大概是一部中篇小说的体量(比如《人间失格》),而 200K 则相当于《呼啸山庄》、《百年孤独》、《骆驼祥子》这类长篇著作了。
以下是 Yi-34B-Chat-200K 对经典文学作品《呼啸山庄》的归纳总结,这部作品中文字数约 30 万字,人物关系错综复杂,但 Yi-34B-Chat-200K 仍能精准地梳理和总结出人物之间的关系。

从行业应用的角度看,Yi-34B-Chat-200K 适合用于多篇文档内容理解、海量数据分析挖掘和跨领域知识融合等,为各行各业应用提供了便利。金融分析师可以用它快速阅读报告并预测市场趋势、律师可以用它精准解读法律条文、科研人员可以用它高效提取论文要点等,应用场景非常广泛。
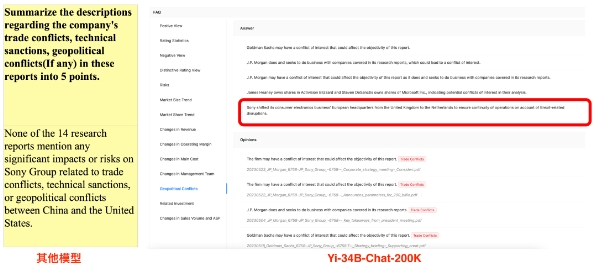
有开发者对比了 Yi-34B-Chat-200K 和某同类模型,从下图我们能看出,对于「请在 18 万字报告中找到地缘政治风险」这一 Prompt,Yi-34B-Chat-200K 给出了正确答案「英国脱欧导致索尼总部搬迁,导致索尼欧洲业务连续性受影响」,而另外一个模型则表示「无地缘政治风险」,未能完成任务。
在另一项任务中,开发者要求某个大模型帮忙「撰写文献综述」,结果,交上来的活只干了一半:
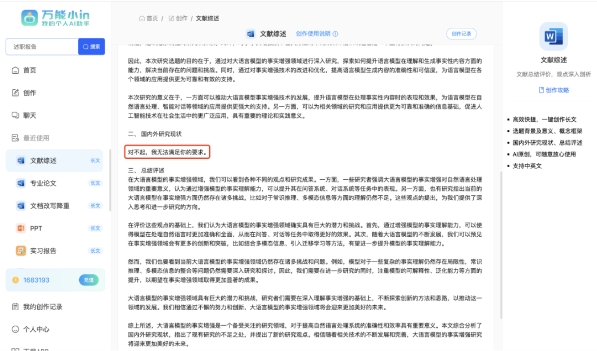
切换到 Yi-34B-Chat-200K 之后,刚才卡住的任务马上成功执行,篇幅控制、翻译准确度、标注格式都符合要求。

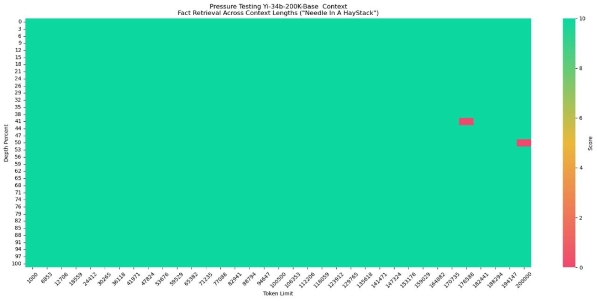
实验数据进一步印证了开发者内测过程中的直观感受:在零一万物针对其进行的「大海捞针」测试中,Yi-34B-Chat-200K 的性能提高了 10.5%,从 89.3% 提升到 99.8%。
拼中文体验,这次赢的显然是 Yi-VL-Plus
大语言模型的持续进步往往也会为多模态大模型注入新的发展生机,尤其近几个月以来,多模态领域迎来「井喷」,大家的目光再次聚焦到了多模态大模型的发展上来。
谷歌 Gemini 原生多模态、Anthropic Claude 3 首次支持多模态能力,随之而来的是,多模态大模型对图像(包括其上文字)、表格、图表、公式的识别、理解能力已经在整体上了一个新台阶。自然而然,这对其他大模型厂商提出了更高的多模态能力需求。
对于零一万物来说,这既是挑战,也是机遇。自成立以来,零一万物在大模型多模态能力上的探索一直在推进,尤其中文场景表现亮眼。
1 月 22 日,零一万物 Yi-VL 多模态语言大模型正式开源,包括 Yi-VL-34B 和 Yi-VL-6B 两个版本,其中 34B 版本在针对中文打造的 CMMMU 数据集上的准确率紧随 GPT-4V 之后,在开源多模态模型中处于领先位置。
现在,Yi-VL-Plus 多模态模型在原有 Yi-VL 基础上迎来全方位升级,进一步提高了图片分辨率,支持 1024*1024 分辨率输入,不仅对图片中文字、符号的识别、理解和概括能力得到前所未有的加强,在部分中文场景的实际体验更是超越了 GPT-4V。眼见为实,我们来详细对比一下开篇提到的这个图文对话示例。
可以看到,Yi-VL-Plus 的回答言简意赅,准确无误,验证了它对图片中文字超强的识别能力;而 GPT-4V 看似回答了一大堆内容,实则废话连篇,除了「羊肉汤烩面」这个招牌之外,它给出的食物显然是基于一般常识推理出来的,并不是它准确看到的。二者高下立判。
在更准确地搞定一般中文场景的图片识别之外,此次 Yi-VL-Plus 的一大特点是大幅增强了对实际生产力场景的支持,既提高了图表(Charts)、表格(Table)、信息图表(Inforgraphics)、屏幕截图(Screenshot)中文字和数字 OCR 的识别准确性,让模型「看得准」;又支持了复杂的图表理解、信息提取、问答以及推理,让模型「答得透」。
我们同样发现,在这些偏生产力场景的任务中, Yi-VL-Plus 的实际体验依然要比 GPT-4V 更好。
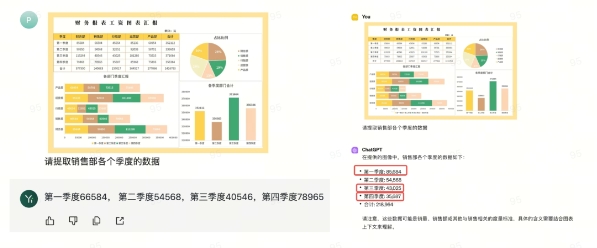
我们来看下面这个中文「财务报表数据提取」任务,Yi-VL-Plus 没有被不同部门的数据所迷惑,精确无误定位并提取到了销售部门各个季度的数据;而 GPT-4V 显然被复杂的表格和柱状图数据难倒了,给出的数据中出现多达三处错误。
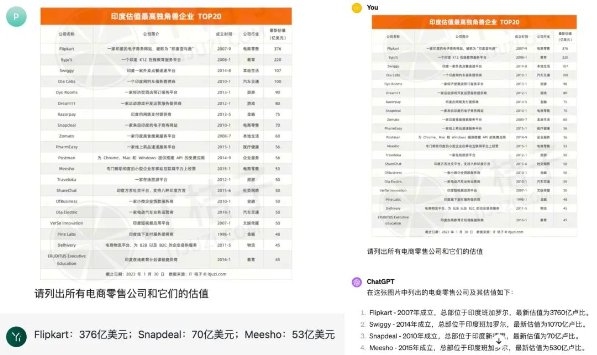
在另外一个中文「图表理解场景」中,Yi-VL-Plus(左)在准确性方面同样击败了 GPT-4V(右),后者混淆了电商零售与本地生活服务的概念。
论「火眼金睛」,Yi-VL-Plus还是更强一点的。
当然,不止中文场景,Yi-VL-Plus 也能轻松处理英文「图表信息提取」任务,在答案准确性方面依然要强于 GPT-4V。
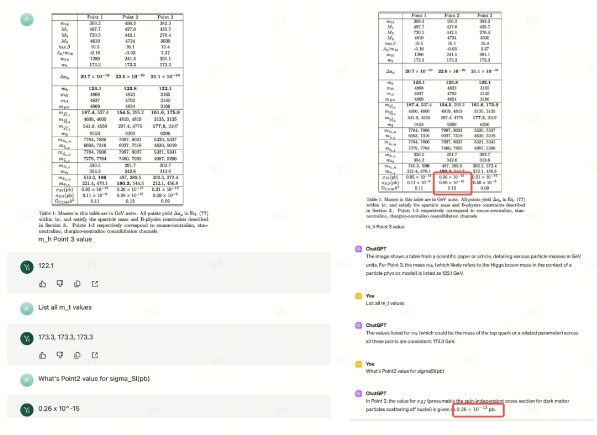
到了「临门一脚」,GPT-4V还是出错了。
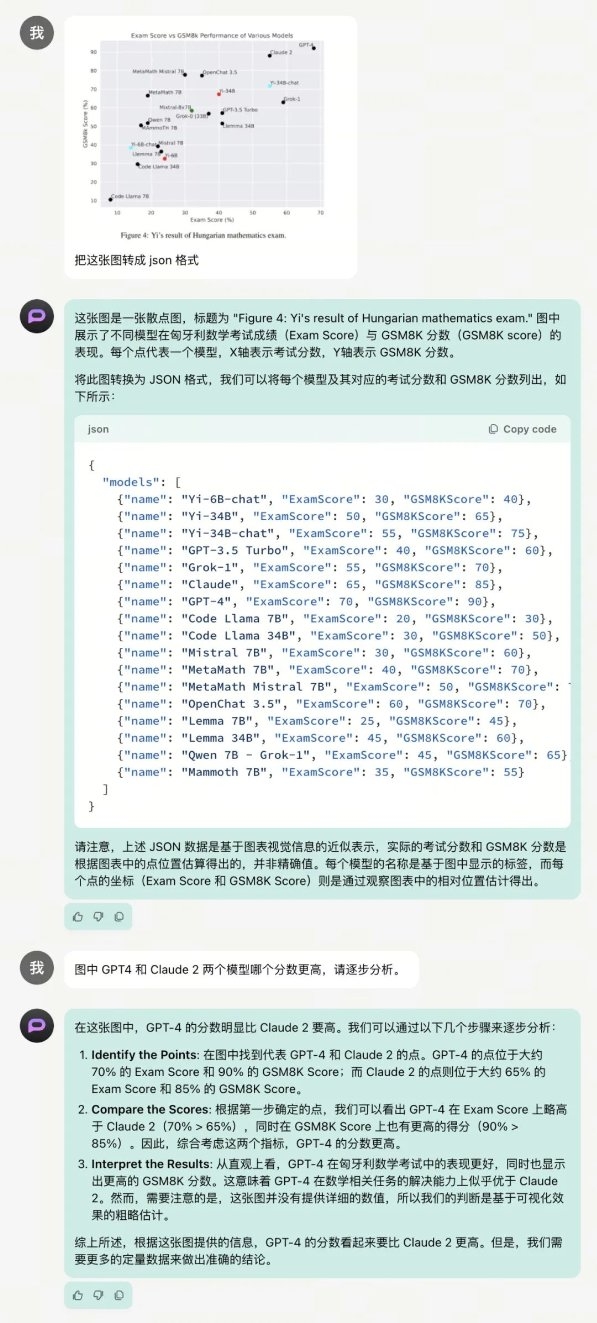
在充分把握图表信息的基础上,Yi-VL-Plus 还能释放其他多模态能力,比如将图表转化为其他格式,诠释了「技多不压身」。
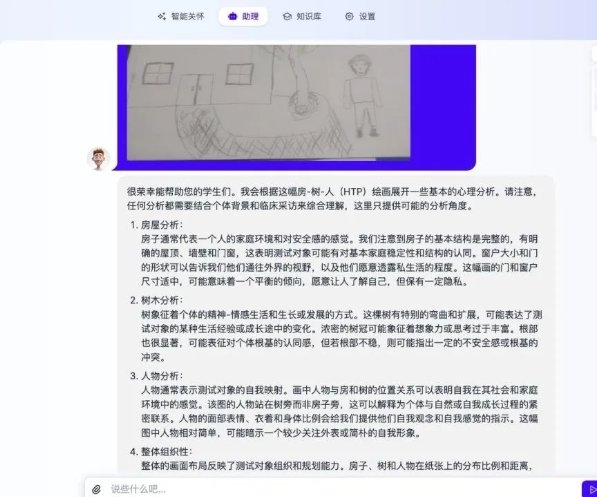
而在下面涉及专业知识学习与解读的案例中,Yi-VL-Plus 同样能给出有模有样的专业回答。可以看到,Yi-VL-Plus 能够结合历史病历和图片信息(脱敏数据),较好地完成对青少年心理健康水平解读。
至此,我们大可以得出这样的结论:中文社区终于迎来了一个性能强大的多模态大模型。尤其是对于普通用户而言,在生产力场景下足功夫的 Yi-VL-Plus 能够成为他们分析图表、分类知识、汇总数据的绝佳辅助工具,对工作效率的提升显而易见。
写在最后
当今,大模型厂商想要在激烈的竞争中胜出,靠的不再只是炫「冷冰冰」的榜单数据,还要不断降低模型使用门槛,为用户「减负」。自然而然,开放 API 成为了很多厂商的选择。
从成立至今,零一万物一方面坚持向公众开源 Yi 系列模型,为开源社区贡献自己的技术力量;另一方面又希望通过开放 API 让包括开发者在内的更多人用上强大的对话、多模态大模型,或用来创作或用于工作,这样反过来又将促进这些模型在更多应用场景中的落地,形成双赢局面。
此前,零一万物 CEO 李开复博士曾表示,零一万物将在 Yi 系列大模型的基础上打造更多 To C 超级应用。此次在开放对话、多模态模型 API 的同时,还强调了开发者工具对促进大模型应用创新的作用,双管齐下,为实现这一目标做好了充足的准备。
零一万物表示,近期将为开发者提供更多更强模型和 AI 开发框架。主要亮点包括:
- 推出一系列的模型 API,覆盖更大的参数量、更强的多模态,更专业的代码/数学推理模型等。
- 突破更长的上下文,目标 100万 tokens;支持更快的推理速度,显著降低推理成本。
- 基于超长上下文能力,构建向量数据库、RAG、Agent 架构在内的全新开发者 AI 框架。旨在提供更加丰富和灵活的开发工具,以适应多样化的应用场景。
显然,零一万物在自家大模型的发展方向上已经有了成熟的思路,未来也势必会走得更远。
评论 {{userinfo.comments}}
{{child.content}}

 {{money}}元
{{money}}元




{{question.question}}
提交







































