

理想车主投诉:理想汽车随意关闭车主APP车控,车主权益谁来维护?
2026-07-21
2022年9月16日,“掘力计划”第24期活动在北京举行,本期活动的主题是“大语言模型应用与实践”。来自中国人民大学的刘勇教授作了题为《大规模图学习中的图对比学习方法与应用》的演讲,向与会者介绍了图对比学习在大规模图学习中应用的相关技术。

刘勇教授来自中国人民大学,准聘副教授、博士生导师。博士毕业于天津大学。从事机器学习研究,特别关注统计机器学习、图表示学习、自动机器学习等。发表高水平论文60多篇,其中以第一作者或通讯作者发表CCF A类文章30余篇,涵盖机器学习领域顶级期刊 JMLR、TPAMI、Artificial Intelligence 和顶级会议 ICML,NeurIPS,ICLR 等。曾获得中国科学院“青年创新促进会”会员(院人才)以及中国科学院信息工程研究所“引进优秀人才”称号。担任国际顶级会议 IJCAI 高级程序委员,NeurIPS、ICML、AAAI、ECAI 等程序委员。主持多项科研基金项目,包括国家自然科学基金青年基金、面上项目、中国科学院基础前沿科学研究计划、腾讯犀牛鸟基金、联通联合项目、华为联合项目等。
视频回放:https://juejin.cn/live/jpowermeetup24
一、图机器学习介绍
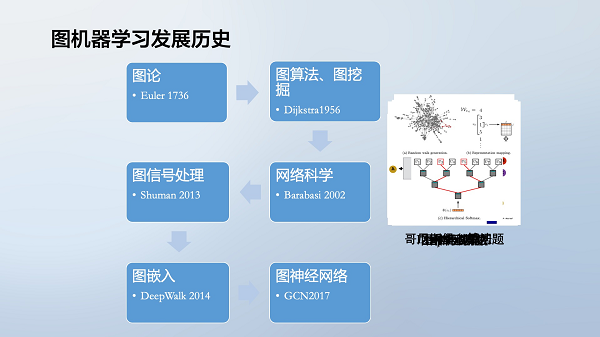
图(Graph)数据结构能够建模实体之间的关系,是表示实体关联的数据结构,因此越来越受到机器学习研究者的关注。
在社交网络、知识图谱、分子化学、蛋白质结构等多个领域,数据具有图结构的特点。将这些图结构数据用于机器学习,形成了图神经网络与图机器学习。
图机器学习专注于挖掘图结构数据中的模式,并进行预测与决策。其与其他机器学习方法的区别在于,图机器学习同时考虑特征和关系,而其他方法多只考虑独立同分布特征。
二、图对比学习方法
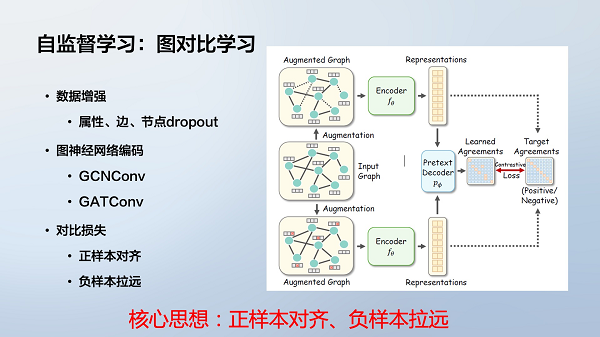
图神经网络虽然表现出色,但其训练依赖大量标注数据。而获得大量标注图数据的成本非常高,因此研究者开始尝试使用无标注数据进行图神经网络的预训练。
图对比学习通过构造正负样本对进行模型训练,属于自监督学习方法之一。它不需要人工标注数据,通过在输入图中进行扰动,产生正负样本对,使模型学习到有用的图表征。
具体做法包括:
● 特征遮挡:随机遮挡节点特征;
● 边删除:随机删除边;
● 子图采样:从大图中随机采样子图。
经过扰动的两个图作为正样本对,原图和无关图作为负样本对,通过拉近正样本距离、拉大负样本距离进行训练。
图对比学习可产生高质量的图预训练模型,对下游任务具有很好的迁移性,可显著提高效果。目前已在分子预测、社交网络等多个领域取得进展。
三、图对比学习中的对齐问题

通过理论分析和实验发现,图对比学习在使正负样本区分开时,也同时增大了正样本之间的距离,导致表示过于对齐,缺乏泛化能力。
为评估图对比学习对下游任务的影响,使用互信息的方法建立了对比学习目标与下游性能之间的上界。实验证明,减小对比学习目标同时保持增强效果,可以获得更好的泛化性能。
四、下一步工作

当前的研究工作主要集中在:
(1)寻找大规模通用图学习基准,类似 ImageNet;
(2)通过数据预处理增强模型泛化能力;
(3)加强理论分析,提高模型稳定性。
期待图对比学习和图神经网络能在更多领域实现突破,真正达到乃至超过大语言模型和大视觉模型的效果。
本次刘勇教授的演讲从图机器学习的发展演变出发,重点介绍了图对比学习在训练大规模图神经网络模型中的应用,并分析了当前的问题与挑战,对于从业者了解图神经网络与对比学习的发展非常有价值。这也充分体现了“掘力计划”活动致力连接学术前沿与产业实践的价值。
掘力计划
掘力计划由稀土掘金技术社区发起,致力于打造一个高品质的技术分享和交流的系列品牌。聚集国内外顶尖的技术专家、开发者和实践者,通过线下沙龙、闭门会、公开课等多种形式分享最前沿的技术动态。(作者:张伟)
评论 {{userinfo.comments}}
{{child.content}}

 {{money}}元
{{money}}元




{{question.question}}
提交






































