别了,摩尔定律!华为“韬定律”如何改写全球半导体的未来
2026-05-29
X86处理器问世42年了,已经进入了不惑之年,回头看看它的发展过程,到底都在哪些方面有了质变呢?
大家都看得到是性能,这些年来X86性能不断进步,最初频率不过5MHz,现在已经增长1000倍到5GHz,也从最初的单核一路扩展到了双核、四核、八核等,这可以说是X86的第一种算力。
第二点就是功能,X86处理器最初就是单纯的CPU,后续不断扩展,20多年前开始整合浮点单元,10年前开始整合GPU单元,它可以看作X86的第二次算力革命。

如今已经进入到了21世纪第三个十年,这几年来人们对算力的要求也不一样了,AI人工智能崛起,各种AI芯片方兴未艾,这些厂商动不动就是吊打CPU处理器,这也让X86处理器有些落寞。
既然这个趋势不可避免,那就拥抱它吧——X86老大Intel这两年来就是这么做的,从10nm Ice Lake处理器开始给X86处理器加入AI加速功能,促成了X86处理器史上第三次算力崛起。
Tiger Lake处理器:三位一体加速AI、6倍AI性能
Intel是最早一家赋予X86 CPU处理器AI加速功能的公司,早在去年的Ice Lake处理器上就首次集成了AI加速,当时是通过DL Boost指令集实现的。
所谓DL Boost,指的是DeepLearning Boost(深度学习加速),深度学习是目前最火热的AI技术之一,但它与CPU、GPU常规的运算指令又有所不同,按照常规方法跑效率很低,而DLBoost是专门用于加速AI运算的指令,因此运算效率非常高,速度要快很多。

DLBoost指令集中主要包括AVX512VNNI以及Bfloat 16,它全面支持Windows ML、Intel OpenVINO、苹果CoreML等框架,兼容目前主流的AI平台,便于开发者在十代酷睿上推进各种AI应用。
根据之前的测试,Ice Lake支持DL Boost之后,在INT8运算相关的AIXPRT测试中,Ice Lake处理器的性能可达前代处理器的 2倍到2.5倍之多。

在Ice Lake小试牛刀之后,Intel在第二代10nm处理器Tiger Lake上进一步加强了AI性能,除了原有的DL Boost及低功耗加速器之外,Tiger Lake上这次的Xe图形架构GPU进一步提升GPU对AI的加速性能,将Ice Lake上的CPU+GPU+GNA的AI加速性能提升到新的高度。

在Tiger Lake处理器上,基于Xe图形架构的内置显卡是其亮点之一,该图形架构是Intel时隔22年之后重返高性能GPU市场的基础,通过Xe图形架构就能同时覆盖笔记本、台式机、工作站、HPC超算等低功耗到高性能图形计算平台。

除了高性能计算之外,AI加速也是Intel的Xe架构不同于其他GPU的地方,Intel用于极光”(Aurora)百亿亿次级超级计算机的GPU也是Xe架构的,代号Ponte Vecchio,它跟Tiger Lake中的Xe GPU只是规模大小不同。
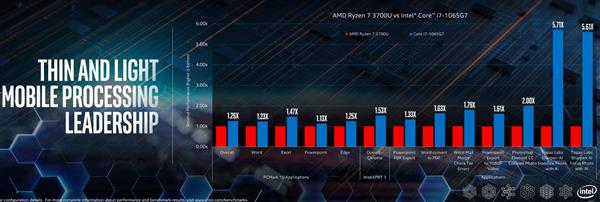
那实际性能如何呢?先不说更强大的Tiger Lake,只需要目前的Ice Lake处理器出马,其AI加速性能就已经达到了竞品的数倍,最高可达6倍性能。
不光是理论性能占优,实际上AI加速在PC上已经有了大量应用,涉及图像、音频、视频、语音等各个领域,很多时候大家可能并没有感觉到而已。

在CES现场,Intel邀请了Adobe公司的开发人员上台,演示了Photoshop软件的AI加速,上图中原图是一张分辨率较低、噪点较多的照片,通过AI加速可以在几秒钟内变成一张个高分辨率、高画质的大图片,细节分明、效果锐利。
基于AI加速,Photoshop软件还可以自动抠图,省心省力,这样下去设计师都要失业了。
除了图片,AI技术在视频处理中也一样可以大显身手,PR软件已经可以靠AI实现横屏与竖屏的自动处理,同样可以提升设计师的效率,简化工作量。
消费级CPU补齐缺失的一环 Intel全平台AI起航
对于AI人工智能的前景,目前没人怀疑它会在未来改变人类的科技树,不同的是之前大部分公司都是通过专用AI芯片来跑AI加速,不认为CPU这样的通用处理器适合加速AI,但是Intel做的有点不一样,在两代10nm处理器上都不断加强AI算力,补齐了消费级CPU没有AI加速的这一环。
去年12月中旬,Intel公司宣布斥资20亿美元收购了以色列初创公司Habana,后者是由David Dahan和Ran Halutz于2016年创立的,总部在以色列,致力于提高AI芯片的处理性能并降低其成本和功耗,其AI芯片主要针对深度神经网络训练的特定需求,更适合云端AI训练。

收购Habana公司之后,Intel又获得了一种AI加速芯片——AI推理及AI训练专用芯片。如果再把之前Intel已有的AI相关芯片联系起来,那么大家就可以看到Intel已经在全平台芯片上推进了AI战略。
CPU处理器中,新一代酷睿及至强处理器都开始支持DL Boost为基础的AI加速指令,FPGA中有Agilex系列AI芯片,神经网络芯片有Moviduis以及Nervana系列,GPU加速的AI芯片有Xe图形架构,可以说Intel已经集齐了各种各样的AI芯片,不论哪种AI芯片都有自己的全套解决方案。
这种大面积撒网的布局使得Intel在未来的AI市场竞争中有更强的底气,也更容易发挥协同效应,CPU可以跟GPU、FPGA芯片搭配,灵活应对高性能或者低功耗等AI解决方案,反正从PC到工作站再到数据中心、超算,从本地到云端,从训练到推理,业界需要什么样的AI方案,Intel这边就是“全都有”。

Intel的AI之道:全AI芯片打地基 OneAPI开路
Intel拥有的多种AI芯片中,除了CPU、GPU是自己研发之外,FPGA、Moviduis、Nervana及Habana都是收购来的,不过这也没关系,Intel拥有地球上最先进的制程工艺,这些芯片升级改进之后很快都会使用自家的先进工艺生产,FPGA、Moviduis、Nervana等芯片已经这样做了,陆续使用Intel自己的14nm、10nm及未来的7nm工艺生产。

在解决AI芯片之后,Intel还在推OneAPI软件战略,简单来说就是通过一套开发工具满足不同平台、不同芯片的软件开发,这是Intel“软件先行”战略的重要体现,Intel相信这一战略将定义和引领一个人工智能日益融合、异构及多架构的编程时代。
随着Intel硬件及软件战略的推进,毫无疑问未来AI会成为各种芯片算力的关键。就酷睿处理器来说,AI也成为CPU、GPU标配算力,而且它的性能增长潜力要比传统计算更大,未来几年里动辄数倍的性能提升会是常态。
---------------------------------------------------------
免责声明:
1.本文援引自互联网,旨在传递更多网络信息,仅代表作者本人观点,与本网站无关。
2.本文仅供读者参考,本网站未对该内容进行证实,对其原创性、真实性、完整性、及时性不作任何保证。
评论 {{userinfo.comments}}
{{child.content}}

 {{money}}元
{{money}}元




{{question.question}}
提交