11000mAh电池+10000nits高亮屏,“耐用神机”荣耀X80 Pro Max发布
2026-06-22

随着企业数字化转型战役打响,企业数据势必会迎来井喷发展,而且各个系统交叉分析,数据使用成本会变得越来越高,急需一站式数据解决方案,包括如下几点:
P级别存储规模:数据的集中式管理,包括原有的结构化数据存储,以及数字化转型后越来越多的非结构化如用户行为日志、图片、视频、文档接入,大数据应用将嵌入越来越多的业务场景;
T级别计算能力:大规模加工预、测计算,如基于订单、合同、用户画像等将定义越来越多的超级大宽表(可能上千维度)汇总加工计算,以及T级别条码信息扫描;
同源异构数据访问:数据的存储将会多样化,比如原始区OGG过来表的在Oracle,而支持key-V快速查询的条码信息存储在Hbase,这些跨库的数据在做交叉分析时,我们只需要通过查询引擎Spark、Hive等,直接读取本地化元数据信息即可实现交叉分析,但实际数据存储可能在hdfs、hbase或者Oracle等多个环境;
大吞吐数据管道:支持将海量业务数据快速汇聚到数据湖,供下游大数据分析计算,模型预测,如果时效跟不上预测在准也失去价值了;
基于以上,我们规划数据湖建设思路。
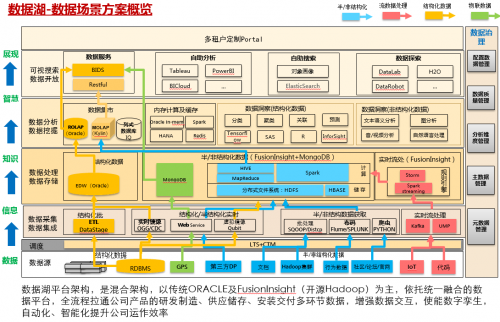
数据湖平台简介
数据湖平台是一套混合架构,以传统ORACLE及FusionInsight(基于开源Hadoop)为主,依托统一融合的数据平台,全流程拉通公司产品的研发制造、供应储存、安装交付多环节数据,增强数据交互,使能数字孪生,自动化、智能化提升公司运作效率。
该平台围绕数据分如下三大逻辑模块:

系统架构如下:
数据建设准则
数据接入原则
以应用驱动为主,优先建设高价值数字孪生项目
入湖数据必须有数据管理部认证,发布对应数据资产标准,匹配对应数据责任人
数据建模原则以原始数据、清洗整合数据、三范式结构、服务化款表逐级向上规范
整体平台需符合高可用、平行扩容原则,符合业务3-5年的数据规划
数据湖指导思想
数据资产稳定可靠是第一原则,其次满足业务数据使用的时效性、完整性是提升ROADS体验的必备要求。
大数据只有开放生态才可能最大化发挥价值,订单不拉通生产制造、交付验收,就难以预估产能周期、用户期望等,我们必须数据开放,才能提供更优质的数据服务。
大数据膨胀迅猛特别是Iot应用的普及,提升数据精度才能发现更多生产问题,AI算法也需要大数据训练模型,我们需要拥抱开源,持续引入工业界优秀平台提升自己。
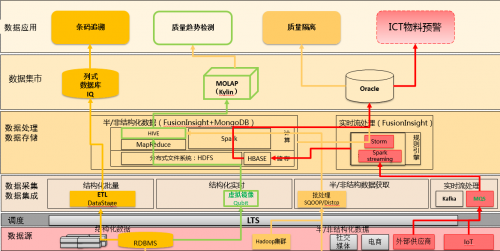
典型数据应用场景
数据湖构建了数据收集、计算处理、数据服务的一站式数据中台服务,如何建设高效的数据集成,并对数据有序的有结构的储存,避免数据的重复建设和不一致问题,保证数据的完整、一致、可行,一直是大数据系统不断追求的目标。
下图按应用场景,对数据流程、处理平台进行的标注:
(绿色)结构化数据通过批处理、虚拟镜像到Hive数据,再通过Kylin预处理将数据储存在Cube中,封装成RESTAPI服务,提供高并发亚秒级查询服务,监测物料质量情况;
(红色)IoT数据,通过sensor采集上报到MQS,走storm实时分拣到HBase,通过算法模型加工后进行ICT物料预警监测。
(黄色)条码数据通过ETLloader到IQ列式数据湖,经过清洗加工后,提供千亿规模条码扫描操作
IoT数据应用 (数据场景:Sensor数据)
OCX组件:对象类别扩充组件(Object Linking and Embedding (OLE) Control Extension),能将sensor数据转换为消息发送到MQS
MQS(UMP):负责缓存消息数据,消息队列服务(Message Queue Service,简称MQS)是针对华为IT场景打造的专业消息中间件,是企业级互联网架构的核心产品,基于高可用分布式集群技术,搭建了包括发布订阅、消息轨迹、资源统计、监控报警等一套完整的消息云服务。支持全球路由、隔离网络、云间集成三大业务场景。
Storm:hadoop体系流处理平台,负责将MQS数据进行处理分发到Hive、Hbase、Oracle等数据平台储存。
rId28
IT日志数据
获取IT应用如办公内web应用、APP应用等日志数据,通过SDK嵌入实现数据的实时采集,上报到kafka(类同于MQS的消息中间件),然后通过批处理方式进行日志分析、访问性能等统计,或者走Flink进行实时监测计算。
SD质检图片数据(数据场景:非结构化数据)
通过web前台、数据API服务,进行图片数据的上传及查询,图片需要有唯一ID作为标示,确保可检索。海量图片数据以ID为rowkey,储存于Hbase平台,提供快速储存及查询能力。数据资产上有以下方面的构建:
统一索引描述非结构数据,方便数据检索分析。
增加维护及更新时间作为对象描述字段(图片类型、像素大小、尺寸规格)。非对象方式及数字化属性编目(全文文本、图象、声音、影视、超媒体等信息),自定义元数据。
不同类型的数据可以形成了关联并处理非结构化数据
附:数据湖与AI分析应用集成方案:
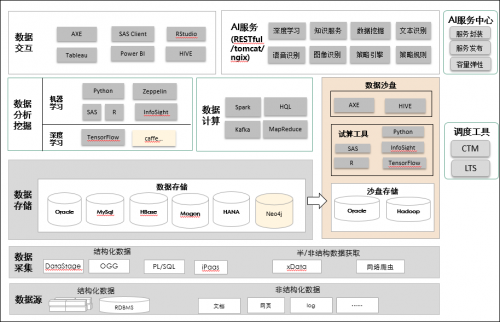
数据存储方案
目前数据湖储存介质以Hadoop和Oracle两套平台为主,总体接入原则:
高价值及高热度数据,优先以ORACLE为主,如FIN数据;
创新性、非结构化数据以Hadoop平台为主,如图片、视频、地图等数据;
贴源建设,如源系统为关系型数据库接入ORACLE,源系统为Hadoop则对接Hadoop;
领域级优先建设原则,如IT、制造、研发代码;
我们按照数据类型、数据规范、适用场景建议如下
ORACLE
Hadoop
Mongo
数据类型
结构化
混合结构(结构、非结构)
非结构
数据规模
30亿级1TB以下
PB规模
10TB级别
BI场景
经营分析类场景
海量储存、流处理、迭代计算场景,比如IT日志分析
GPS地理位置信息数据储存、计算场景
数据设计规范
入湖数据,原则上作为生产环境的全量镜像方式储存,部分数据甚至以数据湖作为第一可信源发布,出于以下考虑:
数据湖体量大,能冷热备生产数据,可将保持较长时间生产环境数据;
OLAP扫描数据量大,多数场景会全量扫描数据,这对OLTP为主的作业系统是不合适,所以我们需要集中在数据湖中进行数据分析工作,和原系统解耦。
数据入湖流程
计算机信息化系统中的数据分为结构化数据和非结构化数据。非结构化数据其格式非常多样,标准也是多样性的,而且在技术上非结构化信息比结构化信息更难标准化和理解。所以存储、检索、发布以及利用需要更加智能化的IT技术,比如海量存储、智能检索、知识挖掘、内容保护、信息的增值开发利用等,所以我们按数据类型分为如下两大流程:
1、结构化数据
结构化数据也称作行数据,是由二维表结构来逻辑表达和实现的数据,严格地遵循数据格式与长度规范,主要通过关系型数据库进存储和管理。
2、非结构化数据
非结构化数据是数据结构不规则或不完整,没有预定义的数据模型,不方便用数据库二维逻辑表来表现的数据。包括所有格式的办公文档、文本、图片、XML, HTML、各类报表、图像和音频/视频信息等等。支持非结构化数据的数据库采用多值字段、了字段和变长字段机制进行数据项的创建和管理,广泛应用于全文检索和各种多媒体信息处理领域。
建模必要要求:统一索引描述非结构数据,方便数据检索分析,可增加维护人员及更新时间作为对象描述字段。
非结构化储存,是对对象方式及数字化属性编目,自定义元数据,关联大量非结构化异构数据采用统一的文件元数据对数据进行建模,每一个元数据可以作为该数据的一个维度,索引引擎会对数据的每个元数据属性进行多维索引,这样不同类型的数据就可以形成了关联并处理非结构化数据(全文文本、图象、声音、影视、超媒体等信息)。
储存平台:HBase、mongoDB、HDFS。
增量方式:支持push、pull两种策略,如选择HBase储存需考虑储存的版本个数方便业务查看历史版本。
如push方式,需业务先将数据以消息方式推送MQS(消息中间件),数据湖负责分拣入湖;
如pull方式,由数据湖主动部署agent上报、或者jdbc等方式去get业务数据,实现组键以flume、爬虫或者数据库驱动为主。
想了解数据湖的更多知识吗?来参加10月10日-12日在上海世博展览中心举行的华为全联接大会吧,众多技术分论坛任你挑选。趁现在,最低单日票价只要150,快来点击华为官网售票页面,开启未来通道吧!
---------------------------------------------------------
免责声明:
1.本文援引自互联网,旨在传递更多网络信息,仅代表作者本人观点,与本网站无关。
2.本文仅供读者参考,本网站未对该内容进行证实,对其原创性、真实性、完整性、及时性不作任何保证。